Dans leur quête pour créer une IA plus intelligente, les entreprises construisent — et alimentent — les plus grands datacenters. xAI a construit le datacenter Colossus de 350 MW à Memphis, qu'ils prévoient d'étendre à 1,5 GW, tandis qu'OpenAI et Microsoft ont prévu de construire le datacenter Stargate de 5 GW au Texas d'ici la fin de la décennie. Ces datacenters individuels rivaliseront avec les installations les plus gourmandes en énergie au monde aujourd'hui, telles que le datacenter Switch de 1,2 GW au Nevada ou la fonderie d'aluminium de Ma'aden de 1,8 GW en Arabie Saoudite.
Et si les tendances se poursuivent, les entreprises pourraient bientôt dépasser cela, avec des clusters d'entraînement projetés pour atteindre 10 GW d'ici la fin de la décennie. Cela est plus important que la capacité de la plus grande centrale électrique des États-Unis, le Grand Coulee Dam, qui correspond à la demande électrique totale pour toutes les puces NVIDIA AI à la fin de 2024.
Mais les services publics ont déjà du mal à répondre à la demande énergétique des hyperscalers IA. John Ketchum, PDG de NextEra Energy, a déclaré l'année dernière qu'alors que les demandes de datacenters "pourraient facilement soutenir une capacité de 15 GW [...], nous n'avons tout simplement pas assez de bande passante [de transmission] dans notre territoire". Mark Zuckerberg a confirmé plus récemment dans un podcast que les contraintes énergétiques sont un goulot d'étranglement de l'IA, affirmant "nous construirions probablement de plus gros clusters que nous ne le faisons actuellement si nous pouvions obtenir l'énergie pour le faire."
Il existe une solution potentielle. L'entraînement décentralisé pourrait permettre aux entreprises de construire des datacenters plus petits — par exemple, près de centrales électriques dont chacune dispose de quelques centaines de mégawatts de capacité de réserve — et de les coordonner comme un seul cluster pour entraîner des modèles plus grands.
La sagesse conventionnelle dans le domaine soutient que les grandes exécutions de pré-entraînement nécessitent de grands bâtiments informatiques contigus.
Planifier un entraînement de dix gigawatts
Tout d'abord, nous devons comprendre où la capacité énergétique pour les datacenters pourrait être disponible aux États-Unis aujourd'hui.
Bien qu'il existe peu d'endroits qui pourraient gérer un nouveau datacenter de 5 à 10 GW, il existe une capacité sous-utilisée existante considérable dans l'infrastructure énergétique. La grille est loin d'être saturée, mais dans de nombreux endroits, les charges de pointe sont relativement rares. Ainsi, l'utilisation de la grille peut être faible, et il y a plus de capacité disponible pendant les périodes de faible charge.
Nous avons compilé une liste de centrales électriques à gaz aux États-Unis avec une capacité de réserve élevée, comme proxy pour la disponibilité énergétique globale dans la zone (voir l'appendice pour plus de détails). La plus grande installation à capacité ajustée trouvée est la Rock Springs Generation Facility en Wyoming — qui dispose d'environ 800 MW de capacité de réserve. Cette centrale électrique est inactive la plupart de l'année, ne produisant que 2% de sa capacité nominale pendant les charges de pointe d'été.
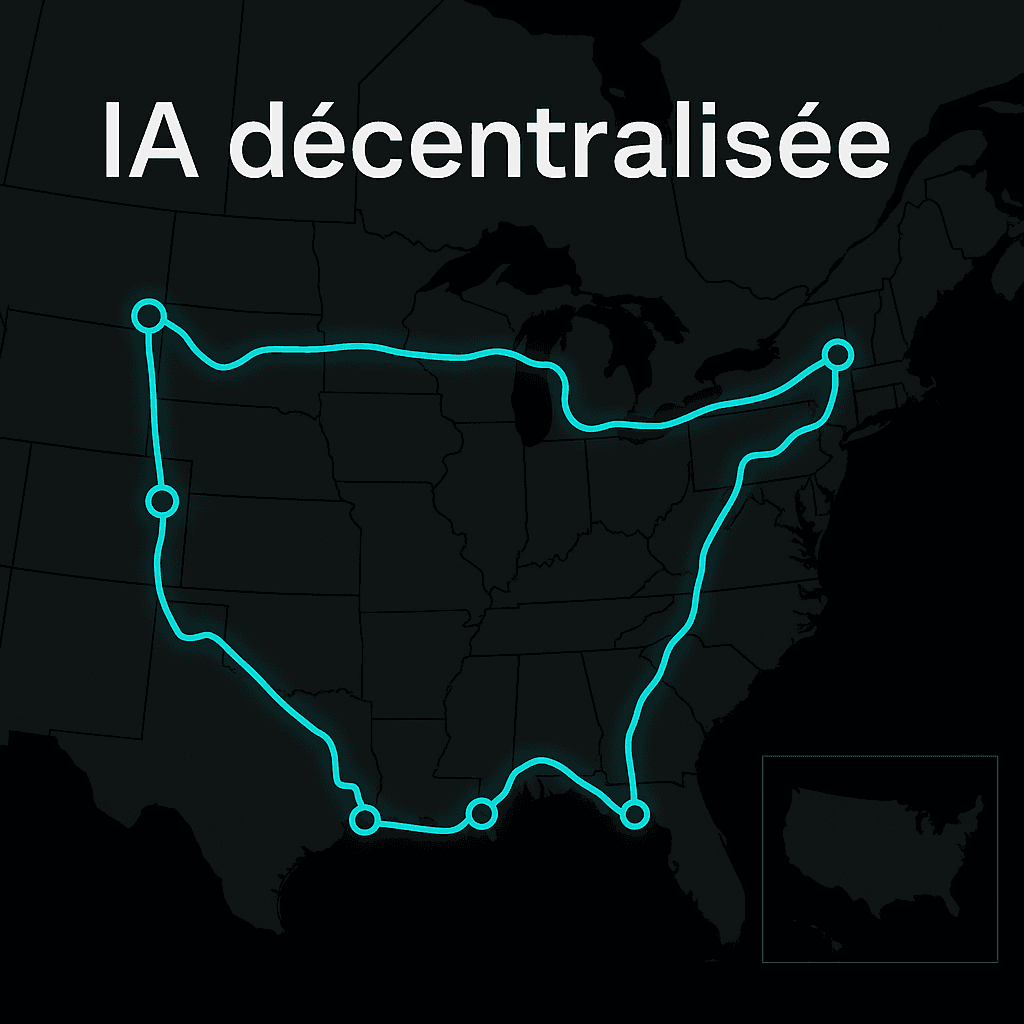
Pour faire évoluer le cluster à 10 GW, nous envisagerons 23 centrales électriques avec une capacité de réserve comprise entre 300 MW et 800 MW à travers les États-Unis, allant de l'Illinois à Philadelphie en passant par la Géorgie. Hypothétiquement, des datacenters pourraient être construits sur ces sites et connectés par 4 800 km de câbles à fibres optiques alimentant 6 gigawatts de puissance.
En pratique, il est peu probable que ces centrales électriques spécifiques soient prêtes à prêter autant de capacité aux datacenters, mais cela suggère que les entreprises devraient être capables d'obtenir autant de puissance à partir d'emplacements proches.
Quel type de modèle entraînerions-nous ?
10 GW pourraient alimenter environ 51 000 serveurs NVIDIA GB200 NVL72. Selon les calculs de Semianalysis, un cluster comme celui-ci pourrait effectuer une exécution d'entraînement de 5e28 FLOP en quelques mois.
Pour référence, Llama 3 405B a utilisé 4e25 FLOP. Nous estimons que les plus grandes exécutions d'entraînement aujourd'hui — en supposant qu'OpenAI entraîne des modèles sur Colossus — utilisent environ 2e27 FLOP. Bien que notre estimation de 5e28 FLOP dépasse largement toute exécution d'entraînement existante, il est possible que ce soit l'échelle que les modèles de frontière atteindront dans quelques années.
Nous concluons que de telles exécutions nécessiteront probablement plusieurs trillions de tokens de données d'entraînement. Epoch AI estime que l'internet public accessible et de haute qualité contient moins de 100 trillions de tokens. L'entraînement à cette échelle devrait donc puiser dans d'autres sources de données. Comme Elon Musk l'a récemment déclaré, "les livres ont probablement environ cinq trillions de tokens et l'internet a probablement environ 100 trillions de tokens, donc vous pouvez épuiser ça, puis vous ne savez pas vraiment quoi faire."
Par conséquent, nous nous attendons à ce qu'une exécution d'entraînement à cette échelle complète les données internet existantes avec des données synthétiques ou vidéo — le pré-entraînement sur des données synthétiques est utilisé aujourd'hui. Les deux nécessiteraient de grandes quantités de calcul en dehors du cluster d'entraînement principal pour générer ou filtrer les données. Pour cette raison, nous modélisons la génération de données comme une exécution d'entraînement de modèle, plutôt qu'un pré-entraînement traditionnel à grande échelle.
L'exécution d'entraînement sur 10 GW pourrait être conceptualisée comme un "run" de génération de données synthétiques alimentant un pré-entraînement de frontière plus petit qui s'exécute sur quelques gigawatts dans un seul datacenter. Alternativement, cela pourrait être l'entraînement d'un modèle qui améliore de manière itérative ses capacités de raisonnement avec test-time compute et auto-amélioration.
Comment décentraliserions-nous l'entraînement ?
Un cluster à grande échelle peut être distribué entre plusieurs datacenters en utilisant le parallélisme de données : différentes copies du modèle sont entraînées sur différents datacenters en utilisant différents lots de données. Périodiquement, les gradients de chaque lot sont synchronisés entre les datacenters et les copies du modèle sont mises à jour en synchronisation.
Nous supposerons que chaque datacenter entraîne un modèle indépendant utilisant le parallélisme de données sur le WAN, chaque datacenter nécessitant une connexion stable et rapide à tous les autres. Voir Besiroglu et al. 2024 et Gu et al. 2024 pour plus de détails.
Nous modélisons notre scénario de manière conservatrice en supposant que chaque datacenter doit se connecter à tous les autres, mais en pratique, une architecture hiérarchique pourrait réduire les coûts d'infrastructure. Les calculs détaillés et les hypothèses sont présentés dans l'annexe B.
L'entraînement décentralisé peut-il maintenir un débit suffisant à très grande échelle ?
Lorsque vous distribuez l'entraînement sur plusieurs datacenters, le débit du système — la vitesse à laquelle il traite les données d'entraînement — dépend de deux facteurs principaux :
- Temps de calcul : Le temps nécessaire à chaque datacenter pour traiter son lot de données
- Temps de synchronisation réseau : Le temps nécessaire pour synchroniser les gradients entre tous les datacenters via le réseau
Si le temps de synchronisation réseau devient trop important par rapport au temps de calcul, le système passera la plupart de son temps à attendre la synchronisation réseau plutôt qu'à effectuer des calculs utiles. Cela réduirait considérablement le débit global.
Pour maintenir un débit élevé, nous devons nous assurer que le temps de calcul domine le temps de synchronisation. Cela peut être accompli de deux manières :
- Augmenter la taille du lot de données traitées entre les synchronisations (augmentant ainsi le temps de calcul)
- Réduire le temps de synchronisation réseau grâce à une infrastructure réseau plus rapide
Dans les sections suivantes, nous examinerons ces deux aspects en détail pour déterminer si un cluster décentralisé de 10 GW peut maintenir un débit suffisant.
Combien de temps pour traiter chaque batch ?
Le temps de calcul par batch dépend de la taille du batch et de la puissance de calcul disponible. Des batchs plus grands signifient plus de temps de calcul, ce qui aide à amortir le coût de la synchronisation réseau.
Cependant, il existe une limite à la taille du batch : si le batch est trop grand, l'efficacité de l'entraînement diminue. C'est ce qu'on appelle la taille de batch critique — la taille de batch au-delà de laquelle augmenter davantage la taille n'améliore plus l'efficacité de l'entraînement de manière significative.
Taille de batch critique
La taille de batch critique est le point au-delà duquel doubler la taille du batch ne réduit pas de moitié le nombre d'étapes d'entraînement nécessaires pour atteindre la même perte. Pour les grands modèles de langage, la recherche suggère que cette valeur se situe généralement entre 1 et 10 millions de tokens par batch.
Pour notre cluster de 10 GW avec environ 51 000 GB200, nous estimons qu'avec une taille de batch critique de 5 millions de tokens, chaque datacenter traiterait son batch en environ 15 à 30 secondes de temps de calcul.
Cela signifie que le temps de synchronisation réseau doit être significativement inférieur à 15-30 secondes pour maintenir un débit élevé. Idéalement, le temps réseau devrait représenter moins de 10% du temps total par batch.
Combien de temps passerons-nous sur le réseau ?
Le temps de synchronisation réseau dépend de deux facteurs clés :
- Latence de propagation : Le temps nécessaire pour qu'un signal voyage sur la distance physique entre les datacenters
- Temps de transmission de bande passante : Le temps nécessaire pour transférer toutes les données de gradient à travers le réseau
Examinons chacun de ces facteurs pour déterminer s'ils constitueraient un goulot d'étranglement.
La latence de propagation serait-elle suffisamment faible ?
La latence de propagation est déterminée par la distance physique entre les datacenters et la vitesse de la lumière dans la fibre optique (environ 200 000 km/s, soit les deux tiers de la vitesse de la lumière dans le vide).
Dans notre scénario avec 23 datacenters répartis sur 4 800 km à travers les États-Unis, la distance maximale entre deux datacenters pourrait atteindre environ 3 000 km. Cela se traduit par une latence aller-retour d'environ 30 millisecondes.
Avec 23 datacenters, le protocole de synchronisation all-reduce nécessite plusieurs tours de communication. En utilisant un algorithme optimisé comme ring all-reduce, le temps de latence total serait d'environ 60-100 ms.
Comparé à notre temps de calcul de 15-30 secondes par batch, cette latence de ~100 ms représente moins de 1% du temps total. La latence de propagation ne devrait donc pas constituer un goulot d'étranglement majeur.
La bande passante pourrait-elle être un goulot d'étranglement ?
La bande passante détermine la vitesse à laquelle nous pouvons transférer les gradients du modèle entre les datacenters. Pour un modèle de plusieurs trillions de paramètres, la quantité de données à synchroniser est substantielle.
Supposons un modèle avec 10 trillions de paramètres (une taille plausible pour une exécution de 5e28 FLOP). En utilisant une précision de 16 bits, chaque paramètre nécessite 2 octets, donc nous devons synchroniser environ 20 téraoctets de données de gradient par synchronisation.
Pour transférer 20 TB en moins de 1-2 secondes (pour rester bien en dessous de notre budget de 15-30 secondes), nous aurions besoin d'une bande passante d'environ 100-200 Gbps entre chaque paire de datacenters.
Heureusement, les connexions en fibre optique modernes peuvent facilement atteindre 400 Gbps ou plus. Des entreprises comme Amazon et Google déploient déjà des connexions intercontinentales à 400 Gbps.
Avec une bande passante de 400 Gbps entre les datacenters, le temps de transmission serait d'environ 0,4 à 0,8 seconde, soit environ 2-5% du temps de calcul total. La bande passante ne devrait donc pas constituer un obstacle majeur.
Conclusion technique
D'un point de vue purement technique, l'entraînement décentralisé à l'échelle de 10 GW semble techniquement faisable :
- La latence de propagation (<1% du temps) n'est pas un problème
- La bande passante (2-5% du temps) est gérable avec l'infrastructure moderne
- Le débit global resterait élevé (>90% d'efficacité)
La vraie question devient alors : quel serait le coût ?
Le coût du réseau est-il réalisable ?
Bien que techniquement faisable, le coût de construction de l'infrastructure réseau pour connecter 23 datacenters à travers les États-Unis serait substantiel. Examinons les composants principaux :
| Composant | Calcul | Coût |
|---|---|---|
| Installation de fibre optique | 4 800 km × $60 000/km | $290M |
| Commutateurs réseau | 23 datacenters × $5M/datacenter | $120M |
| Coût total du réseau | $410M | |
| Comparaison : | ||
| Coût total du datacenter | 51 000 serveurs GB200 × $1,5M | $77B |
| Augmentation du coût réseau | $410M / $77B | +0,5% |
Le coût du réseau — environ 410 millions de dollars — peut sembler élevé en valeur absolue. Cependant, comparé au coût total du datacenter de 77 milliards de dollars, il ne représente qu'une augmentation de 0,5% du coût global.
Cette augmentation marginale suggère que le coût du réseau ne devrait pas être un obstacle majeur à l'adoption de l'entraînement décentralisé, du moins d'un point de vue économique.
De plus, l'infrastructure de fibre optique pourrait servir à plusieurs exécutions d'entraînement au fil du temps, amortissant davantage le coût initial.
Les entreprises adopteront-elles réellement l'entraînement décentralisé à grande échelle ?
Notre analyse montre que l'entraînement décentralisé est techniquement faisable et économiquement viable pour des clusters de 10 GW. Mais cela ne signifie pas que les entreprises l'adopteront nécessairement. Plusieurs facteurs pourraient influencer cette décision :
Facteurs favorables à l'adoption
- Contraintes énergétiques : Les difficultés à sécuriser 5-10 GW en un seul emplacement pourraient forcer les entreprises à se décentraliser
- Coûts marginaux faibles : L'infrastructure réseau n'ajoute que 0,5% au coût total
- Flexibilité : Capacité à utiliser la capacité de réserve existante plutôt que d'attendre de nouvelles centrales électriques
- Résilience : Distribution des risques sur plusieurs emplacements géographiques
Obstacles à l'adoption
- Complexité opérationnelle : Gérer 23 datacenters est plus complexe qu'un seul grand datacenter
- Préférence pour la centralisation : Les entreprises ont tendance à privilégier des solutions plus simples et éprouvées
- Délai de construction : Installer 4 800 km de fibre et coordonner plusieurs sites prend du temps
- Risques réglementaires : Naviguer entre différentes juridictions et réglementations
Notre conclusion : Les entreprises adopteront probablement l'entraînement décentralisé uniquement lorsque les contraintes énergétiques rendront impossible la construction de datacenters centralisés plus grands.
En d'autres termes, tant qu'il sera possible de construire des datacenters de 5 GW, 7 GW ou même 10 GW en un seul emplacement, les entreprises privilégieront probablement cette approche. L'entraînement décentralisé deviendra une nécessité plutôt qu'un choix — une solution de secours lorsque la croissance centralisée atteindra ses limites physiques.
Cependant, une fois que ces limites seront atteintes — et notre analyse suggère que cela pourrait arriver dans les prochaines années — l'entraînement décentralisé pourrait devenir la seule voie viable pour continuer à faire évoluer les clusters d'entraînement d'IA.
Appendices
Appendix A : Emplacements des centrales électriques américaines
Pour identifier les emplacements potentiels de datacenters, nous avons analysé les données de l'EIA (Energy Information Administration) sur les centrales électriques américaines. Nous avons recherché spécifiquement :
- Centrales à gaz naturel avec capacité nominale > 500 MW
- Facteur d'utilisation < 40% (indiquant une capacité de réserve significative)
- Capacité de réserve estimée entre 300 MW et 800 MW
Les 23 centrales sélectionnées sont réparties dans les États suivants : Wyoming, Illinois, Pennsylvanie, Ohio, Géorgie, Texas, et plusieurs autres. La distance totale de fibre nécessaire pour connecter tous les sites en topologie mesh complète est d'environ 4 800 km.
Note : Ces centrales spécifiques servent d'illustration. En pratique, d'autres emplacements avec des caractéristiques énergétiques similaires pourraient être utilisés.
Appendix B : Hypothèses et calculs détaillés
Hypothèses matérielles
- Serveurs : NVIDIA GB200 NVL72 (72 GPU par serveur)
- Consommation par serveur : ~196 kW
- Nombre total de serveurs pour 10 GW : ~51 000
- FLOP par serveur : ~9,8e20 FLOP/s
- Précision : FP16 (16 bits par paramètre)
Hypothèses réseau
- Bande passante par lien : 400 Gbps
- Latence dans la fibre : ~5 µs/km (vitesse de la lumière × 2/3)
- Distance maximale entre datacenters : ~3 000 km
- Protocole de synchronisation : Ring all-reduce
- Coût de la fibre : $60 000/km (installation incluse)
- Coût des commutateurs : $5M par datacenter
Hypothèses d'entraînement
- Budget FLOP total : 5e28 FLOP
- Taille du modèle : ~10 trillions de paramètres
- Taille de batch critique : 5 millions de tokens
- Temps de calcul par batch : 15-30 secondes
- Efficacité MFU (Model FLOPS Utilization) : ~40%
Formules clés
Temps de latence aller-retour = (2 × distance × 5 µs/km)
Temps de transmission = (taille données × 8) / bande passante
Temps total réseau = latence + transmission
Efficacité = calcul / (calcul + réseau)
Pour plus de détails sur les méthodologies de calcul, voir Besiroglu et al. 2024 et Gu et al. 2024.
Notes
Les estimations de consommation énergétique pour les datacenters IA sont basées sur les spécifications NVIDIA GB200 et les rapports publics des entreprises.
Les données sur les centrales électriques proviennent de l'EIA (U.S. Energy Information Administration) Form 860 et Form 923 pour l'année 2023.
Les calculs de temps de synchronisation supposent un protocole ring all-reduce optimisé avec compression de gradients.
Les coûts de fibre optique incluent l'installation, les droits de passage, et l'équipement terminal, basés sur les coûts moyens de l'industrie en 2024.
La taille de batch critique est basée sur les recherches récentes sur l'optimisation de l'entraînement des grands modèles de langage.